El otro día pasó a mejor vida un disco duro externo en el que generalmente hago mis respaldos automáticos. Mientras que consigo otro decidí hacer las copias en una carpeta privada en la computadora que funciona como NAS .
La cantidad de datos es importante, estoy hablando de unos cientos de gigabytes y la primer copia puede durar varias horas.
Rsync y Parallel
Buscando en internet me topé con este script llamado rsync_parallel que me resultó muy interesante.
#!/bin/bash
set -e
# Uso:
# rsp.sh [--parallel=N] [opciones de rsync]
#
# Options:
# --parallel=N Utiliza N procesos paralelos para transferir los archivos.
# El valor por defualt es de 10.
#
# Notas:
# * Requiere GNU Parallel
# * Utilizar este script con ssh-keys = Un montón de solicitudes de contraseña.
# * Primero hace una lista de los archivos que han cambiado, luego parte esta
# lista en N pedazos y le encarga a rsync la copia de cada uno de esos pedazos.
# * Hay que tener cuidado con las con las opciones que pasan a través de rsync.
# las normales va a funcionar, es posible que desee probar opciones extrañas
# por adelantado.
#
# Gracias a rcoup por este script https://gist.github.com/rcoup/5358786
#
if [[ "$1" == --parallel=* ]]; then
PARALLEL="${1##*=}"
shift
else
PARALLEL=10
fi
echo "Utilizando $PARALLEL procesos para la transferencia de archivos..."
TMPDIR=$(mktemp -d)
trap "rm -rf $TMPDIR" EXIT
echo "Calculando la lista de archivos..."
# sorted by size (descending)
rsync $@ --out-format="%l %n" --no-v --dry-run | sort -n -r > $TMPDIR/files.all
# check for nothing-to-do
TOTAL_FILES=$(cat $TMPDIR/files.all | wc -l)
if [ "$TOTAL_FILES" -eq "0" ]; then
echo "Nada que transferir :)"
exit 0
fi
function array_min {
# return the (index, value) of the minimum element in the array
IC=($(tr ' ' '\n' <<<$@ | cat -n | sort -k2,2nr | tail -n1))
echo $((${IC[0]} - 1)) ${IC[1]}
}
echo "Generando los pedazos..."
# declare chunk-size array
for ((I = 0 ; I < PARALLEL ; I++ )); do
CHUNKS["$I"]=0
done
# add each file to the emptiest chunk, so they're as balanced by size as possible
while read FSIZE FPATH; do
MIN=($(array_min ${CHUNKS[@]}))
CHUNKS["${MIN[0]}"]=$((${CHUNKS["${MIN[0]}"]} + $FSIZE))
echo $FPATH >> $TMPDIR/chunk.${MIN[0]}
done < $TMPDIR/files.all
find "$TMPDIR" -type f -name "chunk.*" -printf "\n*** %p ***\n" -exec cat {} \;
echo "Iniciando la transferencia de archivos..."
find "$TMPDIR" -type f -name "chunk.*" | parallel -j $PARALLEL -t --verbose --progress rsync --files-from={} $@
Divide y vencerás
Tiene un enfoque muy interesante, primero obtiene una lista completa de los archivos que se van a copiar y luego divide esa lista en varios archivos de una forma equilibrada.
El total de archivos corresponde al número de procesos concurrentes que queremos trabajar, por default es 10 pero se puede cambiar con un parámetro.
Una vez que tenemos nuestras listas el programa parallel inicia la copia de los archivos con rsync y le entrega una lista de los archivos a cada proceso que se ejecuta simultaneamente.
El problema es el ancho de banda.
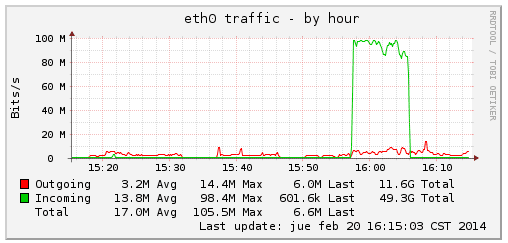
Gráfica del tráfico por hora
El problema es que ahora tengo 10 procesos peleándose el ancho de banda, que lamentablemente es poco en mi caso. Supongo que una copia con una buena velocidad o de un disco duro a otro la copia de archivos volaría.
También pueden notar que el equipo se puede comportar un poco lento, eso depende de los recursos de su computadora. Eso se debe al uso intensivo del disco duro durante la copia de los archivos.
El uso de parallel es interesante, actualmente estoy jugando con el número de procesos a ejecutar. Si utilizo pocos, más o menos sería lo mismo que ejecutar un rsync simple. Si uso muchos, los pedazos serán más pequeños, pero el uso del disco será mayor.

copiando ando | rsync parallel
Les paso el dato por si algún día se les ofrece hacer una copia masiva de archivos.